背景:
本文是学习12c新特性的笔记,主要来源于官方文档和OU教材汇总而成。
什么是临时undo?
Temporary Undo是12c的新特性,如下图所示:
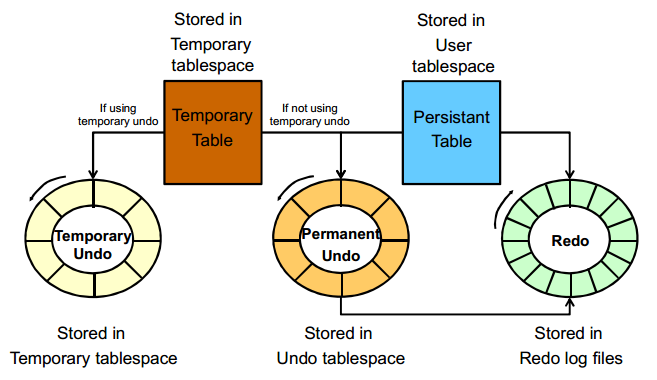
临时表广泛的被用作于为暂存中间结果分配区域,这是因为改变哪些表是比用非临时表快很多的。性能提升主要是因为实际上修改临时表没有redo条目直接产生。然而,在临时表(和索引)上操作的undo任然记录到redo log。临时表的undo,在该临时对象的其生命期的一致性读和事务回滚是有用的。超出此范围的undo是多余的。因此它在redo流中不需要持续。举例来说,事务恢复只是丢弃临时对象的undo。
从12c开始,可以通过把临时表的事务产生的undo,直接在临时表空间中存储独立undo流,来避免在redo流中记录undo。
注意:临时undo segment是会话私有的。它存储属于相应会话的临时表改变的undo
默认情况下,undo记录临时表是存储在undo表空间中,且记录到redo中,这是与undo管理永久表相同的方式。然而,你可以使用TEMP_UNDO_ENABLED初始化参数来从永久表的undo分离临时表的undo。当此参数设置为TRUE,临时表的undo调用temporary undo。